
← Spring Data JPA. Работа с БД. Часть 1
→ Spring Data JPA. JUnit тесты для Services. Часть 3
В прошлом уроке мы создали ERD и на её основе построили Entity. В этом уроке мы научимся создавать слой DAO на основе созданных Entity и Services, разберемся, зачем эти два слоя нужны.

Шаг 0. Подготовка БД
Не забывайте что мы используем MySQL базу данных, поэтому вам нужно установить MySQL сервер и желательно редактор БД MySQL Workbench. Скачать можно тут.
После установки откройте MySQL Workbench, подключитесь к серверу:

После, создайте базу данных, нажав по соответствующем значку:

либо выполнив SQL запрос:
CREATE SCHEMA `testdb` DEFAULT CHARACTER SET utf8mb4 ;
После этого можно переходить к созданию репозиториев. Нам не придётся создавать таблицы в БД их проект создаст сам.
Шаг 1. DAO либо Repository
Для начало разберемся что же такое DAO?
DAO (Data Access Object) – это слой объектов которые обеспечивают доступ к данным.
Обычно для реализации DAO используется EntityManager и с его помощью мы работаем с нашей БД, но в нашем случае это система не подойдет, так как мы изучаем Spring Data нам нужно использовать её средства иначе незачем он нам.
Spring Data предоставляет набор готовых реализаций для создания DAO но Spring предпочли этот слой называть не DAO, а Repository.
О самом фреймворке Spring Data вы можете почитать тут.
Теперь давайте для каждого Entity создадим Repository, который позволит оперировать объектом в БД.
Создать Repository довольно просто, даже больше чем просто, давайте создадим для Bank entity его Repository и увидим на сколько все просто:
package com.devcolibri.dataexam.repository;
import com.devcolibri.dataexam.entity.Bank;
import org.springframework.data.jpa.repository.JpaRepository;
public interface BankRepository extends JpaRepository<Bank, Long> {
}
В 6-й строке видно что мы создали интерфейс с именем BankRepository и унаследовались от JpaRepository.
JpaRepository – это интерфейс фреймворка Spring Data предоставляющий набор стандартных методов JPA для работы с БД.
Ну создали интерфейс и что дальше? Спросите вы. На основе этого интерфейса Spring Data предоставит реализации с методами, которые мы использовали в Entity Manager, немного позже вы увидите пример использования Repository.
Для создания Repository нужно придерживаться несколько правил:
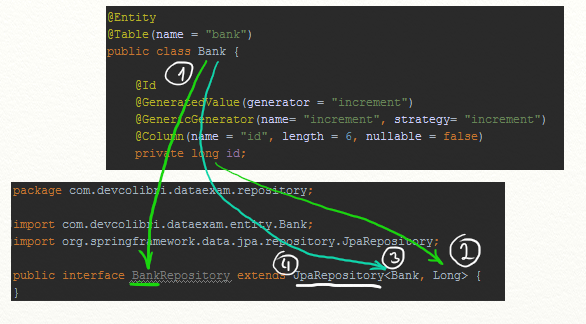
1 – Имя репозитория должно начинаться с имени сущности NameReposytory (необязательно).
2 – Второй Generic должен быть оберточным типом того типа которым есть ID нашей сущности (обязательно).
3 – Первый Generic должен быть объектом нашей сущности для которой мы создали Repository, это указывает на то, что Spring Data должен предоставить реализацию методов для работы с этой сущностью (обязательно).
4 – Мы должны унаследовать свой интерфейс от JpaRepository, иначе Spring Data не предоставит реализацию для нашего репозитория (обязательно).
Давайте продолжим создание Repositories для других сущностей.
Создаем BankAccountRepositroy для BankAccount:
package com.devcolibri.dataexam.repository;
import com.devcolibri.dataexam.entity.BankAccount;
import org.springframework.data.jpa.repository.JpaRepository;
public interface BankAccountRepositroy extends JpaRepository<BankAccount, Long>{
}
Создаем ClientRepository для Client:
package com.devcolibri.dataexam.repository;
import com.devcolibri.dataexam.entity.Client;
import org.springframework.data.jpa.repository.JpaRepository;
public interface ClientRepository extends JpaRepository<Client, Long> {
}
Создаем WorkerRepository для Worker:
package com.devcolibri.dataexam.repository;
import com.devcolibri.dataexam.entity.Worker;
import org.springframework.data.jpa.repository.JpaRepository;
public interface WorkerRepository extends JpaRepository<Worker, Long> {
}
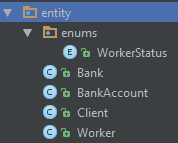
В результате мы получим набор следующих Repositories:
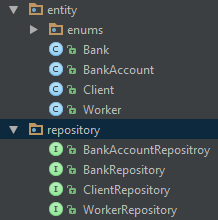
По сути, теперь у нас есть слой обеспечивающий доступ к данным в БД.
Шаг 2. Создание Services
И так мы разобрались зачем нужны DAO/Repositories, для обеспечение доступа к данным, в нашем случае это БД MySQL.
Но напрямую использовать Repositories для получение данных на Пользовательский Интерфейс не принято и считается плохим тоном, для этого были придуманы Services.
Service – это Java класс, который предоставляет с себя основную (Бизнес-Логику). В основном сервис использует готовые DAO/Repositories или же другие сервисы, для того чтобы предоставить конечные данные для пользовательского интерфейса.
Давайте создадим пакет service и в нем создадим наш первый сервис который будет предоставлять конечные данные для пользовательского интерфейса.
Я создам сервис для сущности Bank по аналогии делаются другие.
Создаем новый интерфейс BankService:
package com.devcolibri.dataexam.service;
import com.devcolibri.dataexam.entity.Bank;
import java.util.List;
public interface BankService {
Bank addBank(Bank bank);
void delete(long id);
Bank getByName(String name);
Bank editBank(Bank bank);
List<Bank> getAll();
}
В этом интерфейс мы указали, какие методы нам будут нужны для написания бизнес-логики проекта.
Теперь создаем в этом же пакете, новый пакет impl в котором будут лежать реализации всех интерфейсов. Структура сервиса и его реализации:
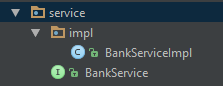
Давайте создадим BankServiceImpl который будет реализовывать BankService интерфейс:
package com.devcolibri.dataexam.service.impl;
import com.devcolibri.dataexam.entity.Bank;
import com.devcolibri.dataexam.repository.BankRepository;
import com.devcolibri.dataexam.service.BankService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class BankServiceImpl implements BankService {
@Autowired
private BankRepository bankRepository;
@Override
public Bank addBank(Bank bank) {
Bank savedBank = bankRepository.saveAndFlush(bank);
return savedBank;
}
@Override
public void delete(long id) {
bankRepository.delete(id);
}
@Override
public Bank getByName(String name) {
return bankRepository.findByName(name);
}
@Override
public Bank editBank(Bank bank) {
return bankRepository.saveAndFlush(bank);
}
@Override
public List<Bank> getAll() {
return bankRepository.findAll();
}
}
Теперь разберем, что же мы тут написали:
14 строка – это аннотация которая позволит Spring инициализировать наш сервис;
15 строка – объявление нашего сервиса (обратите внимание, что это интерфейс, а не реализация), который позволит нам использовать его бизнес-логику;
19 строка – тут мы сохраняем Bank в БД используя метод saveAndFlush, используя просто save() мы сохраняем запись но после вызова flush данные попадают в БД;
26 строка – удаление Bank по его id;
31 строка – этот метод не предоставляется Spring Data в следующем шаге мы рассмотрим как его сделать;
36 строка – update можно сделать тем же методом что и сохранение, так как hibernate умный, и он проверит, есть ли запись в БД, которую мы хотим сохранить, если есть, то он её обновит;
41 строка – получаем все данные с БД, а именно все банки.
Шаг 3. Кастомный метод в Spring Data
И так, в реализации BankService есть метод getByName(), который должен получать Bank по имени, в стандартных средствах Spring Data нет такой возможности, поэтому мы напишем свой кастомный метод.
Для этого зайдите в интерфейс BankRepository и там напишите следующий метод:
public interface BankRepository extends JpaRepository<Bank, Long> {
@Query("select b from Bank b where b.name = :name")
Bank findByName(@Param("name") String name);
}
В строке 3 мы используем аннотацию @Query которая позволяет создать SQL запрос, но этот запрос содержит параметр :name, его иы проставляем в структуре метода findByName() используя аннотация @Param в параметре которой мы указываем имя параметра запроса name.
Spring Data на основе предоставленных данных в аннотациях сам предоставит реализацию этого метода, и это замечательно, так как теперь мы его можем использовать:
@Override
public Bank getByName(String name) {
return bankRepository.findByName(name);
}
И вот финальная структура проекта:
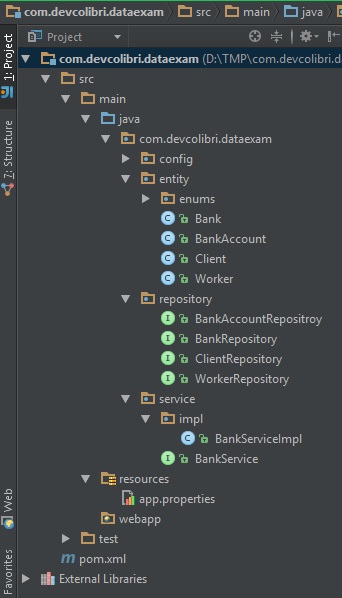
Смотрите в следующем уроке, как тестировать Сервисы:
На этом все, качайте исходники в начале урока, разбирайтесь, если что-то непонятно, то все вопросы в комментарии.
← Spring Data JPA. Работа с БД. Часть 1
→ Spring Data JPA. JUnit тесты для Services. Часть 3
Также читайте: «Быстрый старт в Spring Security»
ПОХОЖИЕ ПУБЛИКАЦИИ
- None Found
Рекомендуемые курсы

Профессия Android разработчика
ОТКРЫТО 697
Android программирование для начинающих
ОТКРЫТО 2244


50 комментариев к статье "Spring Data JPA. Пишем DAO и Services. Часть 2"